Me animo con otro tutorial después de haber creado el anterior y espero nuevamente que os guste y os sirva de ayuda. En esta ocasión vamos a explicar un poco qué es eso de los procesos y los hilos de ejecución, o hebras o threads... como los quieras llamar. Ten en cuenta, que todo el software que ejecutas necesita una serie de procesos y/o de hilos que son unidades fundamentales de procesamiento. El scheduler o planificador del kernel Linux las gestionará e irá añadiendo a la cola para que la CPU las vaya ejecutando, accediendo a los datos e instrucciones almacenados en la memoria RAM. Bien, esto es una forma resumida y sencilla de explicar a groso modo el funcionamiento.
Procesos
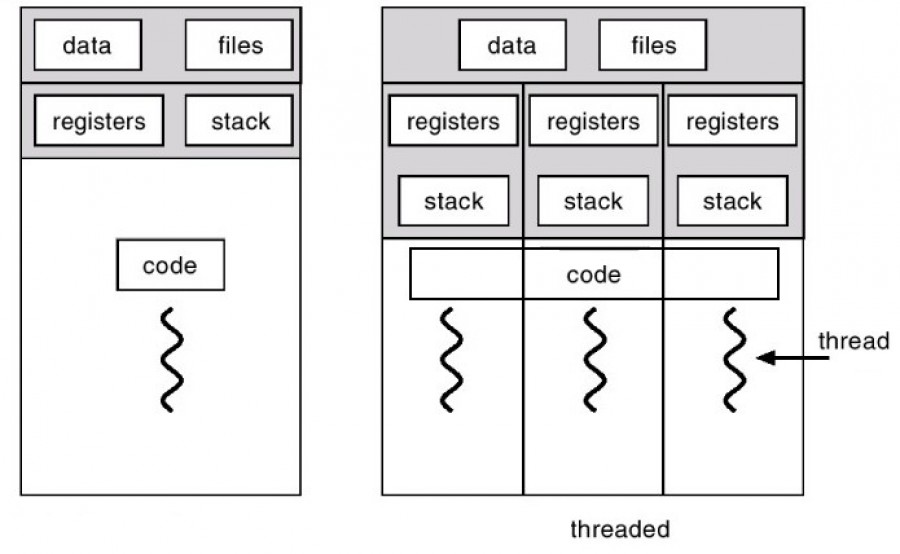
Pero... ¿qué es un proceso? En los modernos S.O. se trabaja con procesos, que es cómo el sistema trata a programas o tareas específcias en ejecución. Cada uno de ellos posee un espacio de direciones asociado en el que puede leer y escribir en memoria virtual (ya que puede que no se encuentre en la RAM, sino en la memoria de intercambio o Swap y se vaya moviendo de una a otra en función de la prioridad y lo que dicte el planificador). En dicho espacio se almacenarán las instrucciones (código) y datos (constantes, variables,...) que el proceso debe manejar para poderse ejecutar, y por supuesto también su pila o stack. Cuando uno de estos procesos es asignado a una unidad de procesamiento o núcleo de la CPU, ésta comenzará a ejecutarlo y para ello se necesita asignar un conjunto de registros para cada proceso, cargar un registro PC (Program Control) que irá apuntando a la siguiente instrucción del código del programa que se debe ejecutar tras la que está ejecutándose actualmente, un registro SP (Stack Pointer) y otros registros para los operandos que necesita la instrucción. Básicamente, una vez está todo, la unidad de control de la CPU decodificará la instrucción y comenzará a enviar señales al resto de unidades funcionales para que sepan qué deben hacer, como cargar datos desde registros y llevarlos a la ALU o FPU para hacer una operación como una suma, multiplicación, resta, etc. Una vez se consigue el resultado, se pasa a la siguiente instrucción y así hasta completar todo el código de ese proceso. Una vez se tiene, el proceso ha finalizado... Insisto, es una forma simplista de explicarlo, pero no quiero perder a los menos expertos y entrar en temas de superescalaridad, pipeline, OoOE, especulación, etc.
En Linux, podemos conseguir informacion de los procesos en marcha de muchas formas, pero dos de las mas conocidas son con los comandos:
ps aux
top
El primero muestra los procesos en marcha y el segundo es interactivo, es decir, lo muestra en tiempo real y puedes ver la evolución. Por cierto, para salir de top simplemente pulsa Ctrl+C. Si quieres verlos en forma de árbol, y ver la geneaología y de dónde cuelga cada proceso (como sabes, todos vienen del proceso PID=1 o Init, aunque si no usas SysV, este proceso podría denominarse de otra manera, como systemd), puedes usar:
pstree
Una serie de sistems del kernel, como el planificador citado anteriormente y el IPC (Inter-Process Communication) se encargarán de gestionarlos y comunicarlos entre sí entre señales. Unas señales que seguramente te suenen del uso del comando kill para matar procesos ¿no? Bueno, si no es así puedes listarlas con:
kill -l
Estas señales son las que usará el kernel para modificar los estados de los procesos. En sistemas tipo Unix, los estados posibles son 7 (los puedes ver en la columna STAT de la salida de ps):
- Ejecutándose: el proceso está en la cola de ejecución para ser procesado por la CPU.
- Interrumpido: se ha interrumpido por el planificador o está durmiendo a la espera de ser despertado por una señal o temporizador y pasar a ejecutarse.
- Sin interrupciones: dormido como en el caso anterior, pero puede ser despertado por eventos externos.
- Zombie: el proceso ha terminado, pero falta liberar recursos de hardware que tiene ocupados. Es decir, está muerto pero el sistema lo considera vivo... y esos recursos de hardware no pueden ser asigandos a otro proceso.
- Parado: ha sido detenido por una señal de control o por ptrace.
- Exclusivo: cuando se encuentra dormido o en la cola de ejecución esperando a ser despertado sin necesidad de desperar a los otros procesos. Es decir, no es dependiente de otros y puede ser ejecutado sin necesidad de ejecutar otros previamente.
- Terminado: en realidad no se hace referencia a este estado en el sistema, ya que no es un estado en sí, solo es teórico. Es lógico, ya que cuando un proceso ha terminado ya no está en ningún estado, simplemente ha sido ejecutado y ya no existe.
Threads
Eso en cuanto a procesos. ¿Qué sucede con los hilos o threads? No quiero que los confundas con subprocesos, si te fijas en la salida del comando pstree, hay procesos padre e hijos que cuelgan de estos, es decir, que han sido iniciados por el padre. Pero tanto los padres como los hijos no dejan de ser procesos. Los hilos son procesos ligeros en los que se puede dividir cualquier proceso, y por definición sería la unidad de procesamiento más pequeña que puede planificar un sistema operativo. Cada proceso, si se usa programación multithread, está dividido en varios hilos y para que dicho proceso finalice y pase a ese no-estado "terminado" todos y cada uno de sus hilos deben haber finalizado su ejecución.
A diferencia de los procesos, que tenían sus propios recursos asignados, los hilos que pertenecen a un mismo proceso compartirán los recursos asignados a dicho proceso. Aunque, evidentemente de algún modo se deben diferenciar entre sí y eso se consigue asignando a cada thread unos recursos específicos como la pila y el registro de estado de la CPU, etc. Como curiosidad, para generar los procesos, el kernel Linux usa la syscall o llamada al sistema denominada fork(), mientras que para los hilos se usa clone().
Gestión de procesos
Bien, ahora que ya sabemos qué son los procesos e hilos, vamos a ver cómo Linux los gestiona. Y antes de eso, debemos conocer qué es el contexto. Resulta que el planificador irá moviendo los procesos o hebras de la cola de ejecución según la prioridad necesaria. Por eso, si un proceso poco prioritario está en la cola y aparece otro con mayor prioridad, puede sacar al primero de la cola e introducir al segundo. En caso de interrumpir el proceso/hebra, se necesita guardar su información en algún lugar para luego poderlo recuperar. Eso se hace en una parte de la memoria que guardará su estado y que junto con el programa, se conoce como PCB. Todo esto, unido a una serie de algoritmos implementados por software que compondrán el planificador, hará que la gestión de los procesos sea transparente para el usuario y que nosotros solo nos dediquemos a abrir y cerrar apps o realizar tareas dejándole toda la tarea al kernel.
Sin entrar en demasiados detalles de qué es /proc, simplemente que sepas por el momento que es un espacio o interfaz para el usuario en la que el kernel nos muestra la información de procesos. Si te diriges a ese directorio verás un montón de ficheros y directorios numerados. Cada directorio pertenece a un proceso. Por ejemplo, el directorio 575 corresponde con el proceso PID=575. Dentro de dicho directorio, o cualquier otro (solo es un ejemplo), encontrarás unos ficheros como:
- cmdline: nombre del programa o comando que inició el proceso
- cwd: enlace simbólico al directorio de trabajo del proceso
- environ: nombres y valores de variables que maneja el proceso
- exe: enlace simbólico al ejecutable original
- fd: directorio con el enlace hacia el descriptor de fichero
- fdinfo: directorio con entradas que describen la posición y banderas del descriptor
- maps: información sobre el mapeado de ficheros y bloques
- mem: binario que representa la memoria virtual usada por el proceso
- root: enlace hacia el directorio raíz del proceso
- status: información del estaod del proceso y uso de memoria
- task: enlaces duros para cualquier tarea...
Bien, si volvemos al tema de los procesos y demás, ya sabes que puedes conseguir también información de ellos con:
ps aux
O la sintaxis equivalente:
ps -ef
Veremos los procesos en marcha listados con una serie de columnas con información. Si usas la opción -u de ps seguida del nombre de usuario solo se listan los procesos de dicho usuario. Por ejemplo:
ps -u root
En cualquier caso, las columnas que nos muestra son:
- USER: el usuario al que pertenece el proceso.
- PID: el ID o identificador del proceso.
- %CPU: porcentaje de CPU usado.
- %MEM: porcentaje de memoria usada.
- VSZ: tamaño de la memoria virtual total usada por el proceso.
- RSS: conjunto de residentes o memoria del proceso que está en la RAM. La otra parte estará en la SWAP.
- TTY: la tty en la que se ejecuta
- STAT: el estado del proceso, si recuerdas había 7, mediante letras se mostrará el estado.
- START: cuándo se inició
- TIME: tiempo que dura
- COMMAND: es el programa o binario al que pertenece el proceso.
Y fijate qué curioso, si añadimos una L a nuestras opciones de ps conseguimos un misterioso cambio en las columnas:
ps -efL
Ahora aparecen dos columnas especialmente interesantes para el tema que tratamos. Una es PPID, es decir, el Parent Process ID. Como su nombre indica es el ID del proceso padre del que cuelga este proceso. Pero hay una columna que me interesa aún más, y es LWP (Lightweigh Process). ¿Te suena? Pues sí, es un proceso ligero o thread. En esta columna por tanto aparece el ID del thread. Verás que hay PIDs con un solo LWP, porque no son programas que soporten multithread, pero en otros PID habrá varios LWP para un mismo PID, en ese caso, dicho proceso sí que está fraccionado en hilos.
Y ahora viene la pregunta del millón. ¿Un proceso se puede matar como se matan procesos con kill? La respuesta es NO. Se puede matar a procesos padre o a procesos hijo, lo digo porque incluso en muchos blogs especializados hay verdaderos follones en la terminología y dan a entender que un thread se puede matar con kill de forma independiente y no es cierto. La creación o muerte de los threads solo se puede hacer desde el código fuente, mediante la programación de funciones que los generan o eliminan, pero una vez el programa se está ejecutando no podemos usar kill o ninguna otra herramienta para liquidarlos a nuestro antojo...
Si lo piensas es lógico. Imagina que un proceso que estás ejecutando es la preparación de una tarta. Dicho proceso se divide en 3 threads: la mezcla de los ingredientes para hacer la masa, vertir la masa en el molde y hornear la masa. ¿Podría saltar o eliminar el primer paso de mezclar los ingredientes? Es absurdo, el resultado sería algo erróneo, un molde sin contenido horneado...





Actualizamos los baños en Krasnogorsk