- Mensajes: 34
- Karma: 4
- Gracias recibidas: 23
- (+34) 902 931 064
- (888) 888-1234
- [email protected]
-
Valencia, España
Duda con la legalidad en casos puntuales de extracción de datos (web scraping)
- huw
-
Autor del tema
- Conectado
- Navegador Junior
-

Menos
Más
7 años 4 meses antes #1
De nuevo me encuentro con que el hecho concreto que estoy buscando no está indicado. Y no sé si se puede hacer legalmente de forma automática extraer una definición y la clasificación de una palabra para incluirla en una base de datos sin incurrir en una actividad ilegal.
WordReference tampoco es claro en su aviso legal: www.wordreference.com/english/copyright.asp donde dice algo así como:
Y tampoco sé cómo buscar si esto que planteo es legal o no, o los términos para hacerlo o si para poder hacer estas búsquedas automatizadas o hay que consultar, y cuál es la fórmula para ello, a cada una de las páginas de las que extraer datos para que lo autoricen o no.
¿Alguien puede darme alguna pista?
Como ya comenté en otro hilo:
linuxcenter.es/foro/general/210-nanowrimo-linuxero#1078
, estoy preparando una serie de tutoriales sobre trabajo con cadenas de texto en Python y automatización de publicaciones en redes sociales.
En su momento, me pareció un proyecto divertido de desarrollar y muy agradable para quien quiera aprender a trabajar con frases en Python el hacer un robot que generase oraciones en rima y tuitease y pudiera interactuar con humanos o scripts con un lenguaje lo más natural posible.
Tengo varios artículos preparados, algunos de ellos con scripts que pueden ser útiles y, como digo, divertidos para usar, pero tengo dudas sobre la legalidad de la extracción de datos y no quiero publicarlos sin saber si todo lo que planteo es legal.
Pongo varios ejemplos:
Para enseñar tanto vocabulario como estructuras gramaticales hay que pasarle al programa textos para que aprenda. Entiendo que se puede legalmente automatizar la extracción de datos del proyecto Gutemberg, pero ¿qué pasa con otros textos más modernos? El problema con esto es que puede dar al programa un estilo muy arcaico. El tema es ambiguo, ya que no es extraer textos para publicar luego, sino para que una máquina aprenda. Situación que creo que no está regulada:
www.cedro.org/derechos/limites-y-excepciones
La duda es aplicable tanto a artículos, libros, canciones... como a publicaciones más informales, como redes sociales. Dicho de otra manera, en caso de que se pueda extraer legalmente textos para que aprenda un sistema, ¿de dónde se pueden extraer? Sólo textos con CC o es mucho más genérico.
Una vez que están los textos descargados, para clasificar una palabra que no conocemos, lo normal es acceder a la página de la RAE, donde, además de la definición, nos indica si es adjetivo, sustantivo, verbo... si es verbo, la conjugación del verbo, si es transitivo o intransitivo. Es decir, es un servicio que nos da la oportunidad de enseñar mucho a nuestro programa del mismo modo que podemos aprender los humanos.
La RAE tiene sus aplicaciones:
www.rae.es/noticias/nuevas-aplicaciones-...dispositivos-moviles
y en su página indican cómo acceder directamente a las definiciones:
www.rae.es/noticias/cambios-en-el-acceso...e-la-lengua-espanola
. Sin embargo, no indican nada de la automatización de procesos.
WikiPedia además de que sus contenidos son de libre distribución (
foundation.wikimedia.org/wiki/Terms_of_Use/es
) , ofrece una API para interactuar con ellos:
en.wikipedia.org/w/api.php
, sin embargo, en el aviso legal de la RAE:
www.rae.es/info/aviso-legal
, indica:
En virtud de lo dispuesto en los artículos 8 y 32.1, párrafo segundo, del Real Decreto Legislativo 1/1996, de 12 de abril, por el que se aprueba el texto refundido de la Ley de Propiedad Intelectual, regularizando, aclarando y armonizando las disposiciones legales vigentes sobre la materia, quedan expresamente prohibidas la reproducción, la distribución y la comunicación pública, incluida su modalidad de puesta a disposición, de la totalidad o parte de los contenidos de esta página web, con fines comerciales, en cualquier soporte y por cualquier medio técnico, sin la autorización de la RAE. El USUARIO se compromete a respetar los derechos de propiedad intelectual e industrial que son titularidad de la RAE.
De nuevo me encuentro con que el hecho concreto que estoy buscando no está indicado. Y no sé si se puede hacer legalmente de forma automática extraer una definición y la clasificación de una palabra para incluirla en una base de datos sin incurrir en una actividad ilegal.
WordReference tampoco es claro en su aviso legal: www.wordreference.com/english/copyright.asp donde dice algo así como:
Puede citar pequeñas entradas del diccionario. Si está citando en Internet, por favor cree un enlace a la página.
Y tampoco sé cómo buscar si esto que planteo es legal o no, o los términos para hacerlo o si para poder hacer estas búsquedas automatizadas o hay que consultar, y cuál es la fórmula para ello, a cada una de las páginas de las que extraer datos para que lo autoricen o no.
¿Alguien puede darme alguna pista?
El siguiente usuario dijo gracias: impreza233
Por favor, Identificarse para unirse a la conversación.
- impreza233
-
- Conectado
- Navegador Platino
-
- ¿Quién es Homer? Yo me llamo tipo de incógnito

Menos
Más
- Mensajes: 320
- Karma: 11
- Gracias recibidas: 124
7 años 4 meses antes #2
Un saludo
Yo, de este tipo de temas legales, no te sabría comentarte mucho, ya que no estoy muy puesto. Pero seguiré el hilo con atención.
Un saludo
Por favor, Identificarse para unirse a la conversación.
- huw
-
- Conectado
- Navegador Junior
-
Menos
Más
- Mensajes: 34
- Karma: 4
- Gracias recibidas: 23
7 años 4 meses antes #3
Después de consultar a la RAE y a WordReference, sigo sin respuesta a la RAE, pero WR sí que ha respondido un austero:
"No, we don't allow that. Sorry."
Cuando responda la RAE informaré por aquí.
Por favor, Identificarse para unirse a la conversación.
- alejandro
-
- Conectado
- Administrador
-


Menos
Más
- Mensajes: 100
- Karma: 13
- Gracias recibidas: 74
7 años 4 meses antes #4
Cadena de favores
Hola @huw,
Gracias por la información.
¿Tienes los tuits? y así puede más gente preguntar a la RAE en ese hilo...
(para poner aquí un enlace a twitter, tienes que usar el botón de links del editor, si no te lo bloquea al publicar)
Cadena de favores
Por favor, Identificarse para unirse a la conversación.
- huw
-
- Conectado
- Navegador Junior
-
Menos
Más
- Mensajes: 34
- Karma: 4
- Gracias recibidas: 23
7 años 4 meses antes #5
Tuits a la RAE:
Mi consulta:
https://twitter.com/hacemoswebserie/status/1061903043271315456
Hilo empezado por @LinuxCenterEs en el que luego añadí a la RAE en una respuesta:
https://twitter.com/LinuxCenterES/status/1061740281853370369
Conversación con WordReference:
Mi pregunta:
Consulta legal / legal consultation
Hola:
En el apartado de términos legales de la web de WordReference no indica nada, ni autorizando ni permitiendo, sobre el uso de herramientas de automatización para la extracción de datos de la misma. Tampoco hay una API para facilitar esa acción.
Desde la página de WR se pueden consultar los sinónimos y antónimos a través de navegador. ¿Permiten que esas consultas se puedan hacer de forma automática mediante programas externos no desarrollados, aunque pudieran ser supervisados, por WordReference?
En caso de que así sea, ¿en qué condiciones? Explico las motivaciones y el origen de esta pregunta en el siguiente enlace al foro de LinuxCenter (en español):
linuxcenter.es/foro/general/217-duda-con...e-datos-web-scraping
Hello:
In the section on legal terms of the WordReference website, it does not indicate anything about the use of automation tools for the extraction of data from it. There is also no API to facilitate that action.
From the WR page you can consult the synonyms and antonyms through browser. Do you allow these consultations to be done automatically through external programs not developed by WordReference? It would be for a free program in Python shared in GitLab, so you could see the code and it does not contain anything malicious.
If so, under what conditions? I explain the motivations and the origin of this question in the following link to the LinuxCenter forum (in Spanish):
linuxcenter.es/foro/general/217-duda-con...e-datos-web-scraping
Su respuesta:
No, we don't allow that. Sorry.
Última Edición: 7 años 4 meses antes por huw.
Por favor, Identificarse para unirse a la conversación.
- huw
-
- Conectado
- Navegador Junior
-
Menos
Más
- Mensajes: 34
- Karma: 4
- Gracias recibidas: 23
7 años 4 meses antes #6
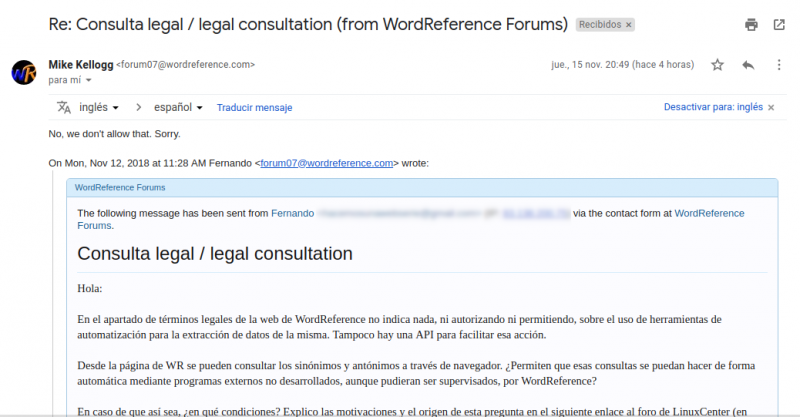
La respuesta de WordReference, por muy extraña que parezca su austeridad, fue así literalmente.
No he borrado ni el "hola", ni el "gracias por su consulta, nos alegramos de que nos tenga en consideración para buscar sinónimos, antónimos y otras consultas lingüísticas" ni mucho menos el "hemos comprobado multitud de consultas desde su IP tanto con wget como con urllib y BeautifulSoup. Pudiendo haber extraído las cadenas que desease, es de agradecer que nos consulte antes de publicar el código de sus scripts."
Adjunto pantallazo:
Por favor, Identificarse para unirse a la conversación.
- gasparfm
-
- Conectado
- Navegador Iniciado
-

- Domador de máquinas

Menos
Más
- Mensajes: 12
- Karma: 1
- Gracias recibidas: 3
7 años 4 meses antes #7
Saludos,
----
Gaspar Fernández
poesiabinaria.net
Qué mal, por el hombre este de los cereales. Con respecto a la RAE, me parece mal que no contesten a algo así. Lo mismo su community manager conoce poco sobre ese tema.
Saludos,
----
Gaspar Fernández
poesiabinaria.net
Por favor, Identificarse para unirse a la conversación.
- huw
-
- Conectado
- Navegador Junior
-
Menos
Más
- Mensajes: 34
- Karma: 4
- Gracias recibidas: 23
7 años 4 meses antes #8
Yo entiendo que una pregunta así al equipo de gestión de comunidades de la RAE es un marrón a un grupo de personas que desempeña un servicio que funciona de maravilla y responden muy rápido en consultas lingüísticas. Yo pregunté hace no mucho que si pythónico y bashismo debía escribirse entrecomillado o en cursiva y me respondieron enseguida que ni lo uno ni lo otro. Incluso me añadieron la tilde a pythónico, que yo también dudaba dado que aunque sea esdrújula, es una españolización de un anglicismo:
https://twitter.com/hacemoswebserie/status/1060310408744067073
Pregunté una noche y me respondieron la mañana siguiente. No hay más que mirar la cuenta de RAEInforma para ver su profesionalidad.
Y entiendo que la pregunta de marras primero, les suene a chino, y segundo, que no quieran o puedan mojarse y le hayan pasado la consulta a otro departamento, bien jurídico o bien técnico.
También es lógico que tengan sus dudas ya que la RAE, aunque tenga una partida presupuestaria de los presupuestos generales del estado, ésta es de un 20% del presupuesto de la Academia, y la mayor parte de la financiación le llega de empresas y fundaciones privadas que quieren que se vean sus logos en cada visita. Si quien extrae esos datos se está aprovechando de la infraestructura que pagan el Banco Santander, la Fundación La Caixa, la Fundación Telefónica y otras entidades y a cambio no devuelve una visita o un visionado de esos logotipos, es de entender que puedan tener cierto recelo, especialmente por desconocimiento, ya que el tema de la extracción de datos, para quien no está acostumbrado a estos términos, suena raro.
La RAE tiene aplicaciones tanto para Android como para iOS, por lo que aunque no tengan una API muy desarrollada, algo tienen programado para acceder a su base de datos.
No quiero insistirles, las cosas de palacio van despacio. Yo sigo haciendo módulos y si cuando tenga una biblioteca operativa y lista para ser usada no puedo nutrirla de los contenidos de la RAE, haré una base de datos colaborativa y una API libre. Y se la ofreceré a la RAE.
Por favor, Identificarse para unirse a la conversación.
¡Atención! Este sitio usa cookies y tecnologías similares.
Si no cambia la configuración de su navegador, usted acepta su uso. Saber más
Acepto
Vea nuestra política de cookies y enlaces de interés aquí

© 2018 Creative Commons By-NC : SLIMBOOK™
«Linux Center» is an authorized independent project with sublicense number 20171225-0743 of Linux® registered trademark of Linus Torvalds.
