
Isaac
Blogger, escritor, electrónico, profesor de Linux, y apasionado de la tecnología...
Conociendo tu CPU desde el terminal

El mundo de la electrónica estuvo separado por un tiempo de la programación cuando solo se creaban circuitos cableados, pero con la aparición de la electrónica programable (con memorias), el software y la electrónica se han vuelto casi uno. El hardware sin software no tendría demasiada utilidad más que para adornar y el software sin un hardware que lo ejecute tampoco tendría sentido alguno. Por eso me he decidido en este tutorial a unir ambos mundos y exponer una serie de trucos, comandos y maneras de optener información del dispositivo de hardware más importante, el cerebro que procesa toda la información: el microprocesador o CPU (Central Processing Unit).
Ya sabéis que existen muchos programas para obtener información de la CPU y del hardware en general, como hardinfo, etc. Pero no es eso lo que busco con este tutorial, sino describir una serie de comandos y ficheros donde encontrar mucha información del microprocesador e incluso comprender un poco mejor cómo está relacionado con el kernel Linux... Y me gustaría hacerlo de una forma muy directa y sencilla para cualquier nivel de usuario, ya que no quiero entrar en demasiados detalles y explicar ciertos directorios del sistema como /proc, etc. Así que, ¡vamos al grano!
1-Listar información de la CPU
Para ello, se puede usar un comando similar a lsusb que usamos comúnmente para los dispositivos USB presentes en nuestro sistema, pero en este caso el comando es el siguiente:
lscpu
Y con él conseguiremos una salida algo más amigable de la información que está contenida en el fichero /proc/cpuinfo. De hecho, si nos dirigimos a este mismo fichero y vemos su contenido haciendo uso de un editor de texto o simplemente del concatenador:
cat /proc/cpuinfo
Obtendremos un resultado similar, la única diferencia es que en el fichero separa las los núcleos y se muestra la información repetida tantas veces como núcleos tenga nuestra CPU, ya que el kernel de Linux en el caso de los multinúcleo no los ve como un único dispositivo.
Por supuesto, también podréis conseguir información de la CPU y mucho más usando comandos como estos dos:
sudo dmidecode
hardinfo
En el caso del segundo, necesitarás instalar el paquete correspondiente, ya que no viene instalado por defecto en las distros. En el caso del primero, puedes usar la opción -t seguida del número de entrada de la tabla de la que deseas extraer la información. Por ejemplo, con -t 11 podríamos extraer la información de entrada la tabla DMI tipo 11...
Más información que podemos extraer, pues por ejemplo, si tenemos instalado cpuid, se puede ver el CPUID, es decir, una serie de información extraída de los registros de la CPU con esta instrucción específica que suelen implementar los x86 (¡ojo! Solo en los x86, ya que otras familias o arquitecturas suelen tener mecanismos diferentes, como eFUSE de IBM, etc.):
cpuid
De hecho, existe una biblioteca (cpuid.h que se puede usando este fichero de cabecera desde un código C, por ejemplo, con #include <cpuid.h>) para los que os interese la programación, que hace uso de esta instrucción de la ISA de estos microprocesadores para conseguir información. Dicho fichero de cabecera o header permite hacer uso en el código fuente de una serie de funciones para conseguir la información qu enecesitamos. Otra forma es usar directamente una inserción de código ASM para invocarla (tipo asm(...); ) o directamente usar solo código ensamblador...
2-Ficheros del sistema
Una vez que hemos visto algunos comandos y formas de extraer información de nuestra CPU, vamos a seguir viendo algunos ficheros muy interesantes que no solo nos van a servir información de la CPU, sino que quizás nos ayuden a entender mejor cómo funciona la CPU y cómo la hace funcionar el propio kernel Linux. Recuerda que el kernel del S.O. es precisamente la interfaz entre el hardware y el software de usuario.
Por ejemplo, con el concatenador podemos ver la información del fichero del directorio /proc donde el kernel almacena info de la CPU:
cat /proc/cpuinfo
Bien, para los menos expertos, vamos a ir desglosando la información que se nos ofrece en la salida. Para ello, pongo un ejemplo concreto que he obtenido de uno PC y entre paréntesis voy a ir explicando lo que significa cada cosa:
processor : 0 (número CPU, que en este caso no es un MP o sistema multiprocesador con varios sockets como los servers,...)
vendor_id : AuthenticAMD (ID del diseñador de la CPU, en este caso AMD)
cpu family : 22 (nº microarquitectura de la que desciende, los diseñadores bautizan con codenames, en este caso Jaguar)
model : 0 (dentro de la microarquitectura AMD Jaguar, este modelo es el 0, con núcleos Kabini)
model name : AMD A4-5000 APU with Radeon(TM) HD Graphics (nombre comercial del microprocesador o APU en este caso)
stepping : 1 (modificaciones que se realizan durante la fabricación del chip, puede haber otroA4-5000 con otro stepping)
microcode : 0x700010b (versión del microcódigo que la unidad de control está usando. Se puede actualizar por el firmware)
cpu MHz : 800.000 (la frecuencia de reloj a la que está funcionando actualmente, no la nominal)
cache size : 2048 KB (tamaño de la memoria cache)
physical id : 0 (ID o identificador físico de la CPU en la placa)
siblings : 4 (coincide con el nºde cores, pero si hubiese tecnología HyperThreading o HT no sería así, contaría núcleos lógicos)
core id : 0 (ID del core 0, habrá otros 1, 2 y 3)
cpu cores : 4 (número de cores presentes)
apicid : 0 (ID del APIC o sistema de gestión de energía)
initial apicid : 0 (idem)
fpu : yes (si contiene o no un coprocesador o FPU (Floating Point Unit))
fpu_exception : yes (si soporta excepciones FPU)
cpuid level : 13 (cantidad de opciones máximas que la instrucción CPUID puede usar para interrogar a la CPU con seguridad)
wp : yes (se refiere al bit WP o Write PRotect del registro CR0, que impone páginas de solo lectura de memoria para kernel)
(Por último tenemos los flags o banderas, que son una serie de tecnologías de gestión de energía, virtualización, instrucciones especiales, seguridad, etc. que soporta la CPU):
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc extd_apicid aperfmperf eagerfpu pni pclmulqdq monitor ssse3 cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt topoext perfctr_nb bpext perfctr_l2 hw_pstate proc_feedback vmmcall bmi1 xsaveopt arat npt lbrv svm_lock nrip_save tsc_scale flushbyasid decodeassists pausefilter pfthreshold
De hecho, si quieres obtener información concreta de un solo parámetro de la CPU, puedes usar el todopoderoso grep para especificar qué quieres conseguir. Imaginate que deseas saber si tu CPU soporta tecnología de asistencia a la virtualización por hardware, eso que Intel llama VT y que AMD denomina AMD-V, o similares, etc. Pues bien, esto no son más que marcas comerciales que los fabricantes o diseñadores han registrado, pero que se refieren a las técnicas que permiten la llamada virtualización completa. Pero, por decirlo de algún modo, el kernel Linux no entiende demasiado de marcas registradas, así que lo tendremos que buscar de otra forma. En el caso de Intel aparece como vmx y en el caso de AMD como svm:
grep svm /proc/cpuinfo
grep vmx /proc/cpuinfo
Y si no sabes si es AMD o Intel...
cat /proc/cpuinfo | egrep '(vmx|svm)'
En cualquiera de los casos, si te devuelve la línea donde ha localizado el flag vmx o svm, quiere decir que sí está soportada la tecnología. Si no devuelve nada, entonces no tiene soporte para ello.
Más cosas que podemos extraer de este fichero, la cantidad de núcleos con:
egrep -i "processor|physical id" /proc/cpuinfo
Otra opción sería con el comando específico:
nproc
Bien, como puedes imaginar las posibilidades con grep y demás son muchas para obtener información concreta de este fichero. Y ahora seguimos con otros ficheros no menos interesantes. Me refiero a /sys/devices/system/cpu. Allí vas a encontrar una serie de directorios y ficheros muy importantes de los que quizás no vayas a extraer tanta información práctica como con el anterior, pero tal vez te ayude a comprender mejor esa relación CPU/kernel. Si ves el contenido, tienes algo parecido a lo siguiente (en función de tu sistema y tipo de CPU):
total 0
drwxr-xr-x 7 root root 0 jun 15 11:17 cpu0
drwxr-xr-x 7 root root 0 jun 15 11:17 cpu1
drwxr-xr-x 7 root root 0 jun 15 11:17 cpu2
drwxr-xr-x 7 root root 0 jun 15 11:17 cpu3
drwxr-xr-x 7 root root 0 jun 15 11:17 cpufreq
drwxr-xr-x 2 root root 0 jun 15 11:18 cpuidle
-r--r--r-- 1 root root 4096 jun 15 11:17 isolated
-r--r--r-- 1 root root 4096 jun 15 12:04 kernel_max
drwxr-xr-x 2 root root 0 jun 15 12:53 microcode
-r--r--r-- 1 root root 4096 jun 15 12:53 modalias
-r--r--r-- 1 root root 4096 jun 15 12:53 offline
-r--r--r-- 1 root root 4096 jun 15 11:17 online
-r--r--r-- 1 root root 4096 jun 15 12:04 possible
drwxr-xr-x 2 root root 0 jun 15 12:53 power
-r--r--r-- 1 root root 4096 jun 15 11:18 present
-rw-r--r-- 1 root root 4096 jun 15 11:17 uevent
Bien, como se peude apreciar, en mi caso hay directorios CPU0, CPU1, CPU2 y CPU3, puesto que mi APU es quadcore. Si por ejemplo entramos en la CPU0 (en el resto el contenido debe ser similar), tenemos esto:
total 0
drwxr-xr-x 6 root root 0 jun 15 11:19 cache
lrwxrwxrwx 1 root root 0 jun 15 11:17 cpufreq -> ../cpufreq/policy0
drwxr-xr-x 5 root root 0 jun 15 12:53 cpuidle
-r-------- 1 root root 4096 jun 15 12:53 crash_notes
-r-------- 1 root root 4096 jun 15 12:53 crash_notes_size
lrwxrwxrwx 1 root root 0 jun 15 12:53 driver -> ../../../../bus/cpu/drivers/processor
lrwxrwxrwx 1 root root 0 jun 15 12:53 firmware_node -> ../../../LNXSYSTM:00/LNXCPU:00
drwxr-xr-x 2 root root 0 jun 15 12:53 microcode
lrwxrwxrwx 1 root root 0 jun 15 12:53 node0 -> ../../node/node0
drwxr-xr-x 2 root root 0 jun 15 12:53 power
lrwxrwxrwx 1 root root 0 jun 15 11:17 subsystem -> ../../../../bus/cpu
drwxr-xr-x 2 root root 0 jun 15 11:18 topology
-rw-r--r-- 1 root root 4096 jun 15 11:17 uevent
Y ya comenzamos a ver nombres interesantes como Power, Microcode, Firmware, cache, CPUIDLE, CPUFreq, etc., nombres que seguro nos sonarán. De hecho, cpuidle y cpufreq son dos partes bastante importantes del kernel Linux, con la que el núcleo hace la gestión de memoria. El módulo cpufreq se encarga de orquestar la frecuencia del procesador en cada momento. Por eso dije anteriormente que 800Mhz no era la frecuencia nominal, sino la que estaba funcionando en ese momento. Eso permite ahorrar energía y hacer funcionar a la CPU a 500Mhz si estás con un editor de texto (demanda menos recursos) o a 3Ghz cuando estás con un videojuego (más exigente con el rendimiento). Y eso lo consigue gracias a los P-States que la CPU soportará, haciendo uso del controlador o driver adecuado. Para orientarte un poco mejor, me estoy refiriendo a eso que los fabricantes bautizan con nombres muy bonitos y comerciales pero que se refieren a la misma tecnología: Intel SpeedStep, AMD Cool'n'Quiet o Power Now!,... ¿te suenan? Pues bien, para escalar la frecuencia y modularla se usan los llamados gobernadores o polticas de gobernacion. Por ejemplo, una cpufreq_performance fuerza a la CPU a trabajar al máximo y una cpufreq_powersave lo hará al mínimo para bajar el consumo y aumentar la autonomía si es un portátil, además de otras políticas intermedias...
Bien, para ver más datos de cómo cpufreq está afectando a nuestro sistema, podemos dirigirnos a uno de estos ficheros de los que hablábamos. Por ejemplo, vamos a ver cómo el núcleo CPU0 está trabajando, y para ello nos vamos a /sys/devices/system/cpu/cpu0/cpufreq y allí podemos ver:
- El núcleo afectado por esta política de energía:
sudo cat /sys/devices/system/cpu/cpu0/cpufreq/affected_cpus
- Ver la frecuencia operativa actual:
sudo cat /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq
- La frecuencia máxima a la que puede escalar (frecuencia nominal, es decir, la que el fabricante te dice que funciona tu microprocesador) y la mínima a la que se puede bajar:
sudo cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq
sudo cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq
- El escalamiento actual de frecuencia que se está aplicando:
sudo cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq
- Incluso el gobernador actual que se está usando:
sudo cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
- La lista de gobernadores disponibles:
sudo cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors
- Y aquí la lista del controlador o driver para estos gobernadores que en función de si es Intel, VIA, AMD, etc., pues será uno u otro:
sudo cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_driver
Por cierto, hasta el momento hemos usado el concatenador simplemente para verlos, pero también se pueden modificar...Por cierto, para mayor comodidad, te aconsejo que instales el paquete cpufreq_utils con herramientas para hacer este trabajo de una mejor forma.
Una vez explicado ese módulo, pasamos al otro, cpuidle. Si accedemos al directorio /sys/devices/system/cpu/cpu0/cpuidle, veremos una serie de directorios como state0, state1, etc. Dentro de cada uno de ellos a su vez hay ficheros que te recomiendo que veas, como: desc, disable, latency, name, power, residency, time, usage. Bien, pues resulta que este módulo del kernel se encarga de apagar o encender núcleos o partes de éstos (unidades funcionales, etc.) para ahorrar. Por ejemplo, si en mi APU el núcleo CPU1 no fuese necesario, cpuidle lo apagaría y así no consumiría. Esto se consigue gracias a los C-States, que nuevamente muchos fabricantes se empeñan en bautizar con nombres comerciales. Para más información:
cpupower idle-info
Tanto el módulo cpuidle como el cpufreq estarán a espensas de la carga de trabajo del kernel, es decir, el scheduler o planificador del núcleo será el que marque un poco si se necesita un rendimiento elevado o si se puede recortar un poco para mejorar el consumo...
Y termino con un último apunte, y es que cpuidle y cpuferq funcionan bien en PCs y servidores o supercomputadoras, pero no en dispositivos móviles como smartphones o tablets. Por eso ARM se puso en marcha para crear un subsistema para Linux llamado EAS (Energy-Aware Scheduling) que une cpuidle y cpufreq en un solo subsistema y el control se hace mucho más eficiente, sin que uno compita o moleste al otro. Claro, menudo lío, imagina que cpuidle está apagando y encendiendo núcleos, cpufreq por otro lado modificando las frecuencias y el kernel Linux con el scheduler balanceando la carga de trabajo que tiene para repartirla entre los recursos activos de hardware. Ese follón puede dar lugar a que en ocasiones se molesten unos y otros sistemas y ocurran cosas indeseadas como que el kernel mande una tarea a un núcleo apagado y este se ponga en modo activo cuando ya había otros activos que podrían asumir esa carga... Pues EAS es la solución a eso!! Y con esto me despido de este tutorial y espero que os guste, más información en mi curso C2GL o en mi libro El mundo de Bitman.
Comprendiendo los menús de configuración del kernel Linux
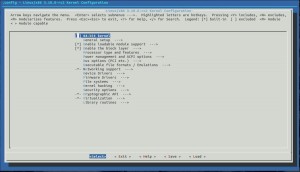
Seguramente habrás encontrado muchos artículos en la red donde explican paso a paso el proceso de descargar un nuevo kernel de kernel.org, configurarlo, compilarlo e instalarlo para actualizar el kernel de tu distribución GNU/Linux con una versión más moderna y no genérica, sino que lo puedas configurar para que se adapte mejor a tus necesidades u optimizarlo. Pero lo cierto es que en esos tutoriales no hablan demasiado de las opciones del menú de configuración, simplemente se limitan a decirte que las dejes todas por defecto, con lo que se consigue un kernel funcional pero muy genérico (similar a los que incluyen las distros en sus repositorios), sin ningún tipo de optimización. Por tanto, si quieres alguna modificación te las tienes que arreglar tú para buscar la información necesaria. El motivo es lógico, y es que cada computadora es un mundo y por tanto la configuración de una específica no tiene porqué funcionar en otra máquina diferente e incluso los usuarios también tienen necesidades diferentes.
Pero entiendo que una ayuda sobre las opciones que puedes ver en el menú de configuración núnca viene mal. Y eso es precisamente lo que vamos a hacer en este tutorial, dejando un poco de lado el procedimiento de descarga del nuevo kernel, compilación e instalación, gestión de módulos, parcheado, e incluso de las diferentes formas de configurarlo que existen (config, menuconfig, kconfig,...). Insisto, no se trata de explicar el proceso, simplemente hacer ver a los nuevos usuarios que lo desconocen qué tienen delante de sus ojos cuando configuran un kernel.
Items del menú de configuración:
Aunque las opciones del menú puedan variar en función de la versión del kernel, yo voy a usar uno bastante actual para describir los diferentes menús que nos podemos encontrar:
- 64-bit kernel: aquí podemos seleccionar el soporte para los 64-bit en nuestra arquitectura, si no lo marcamos funcionará como un sistema de 32-bit. Como sabes, tanto las nuevas ISA AMD64 (o EM64T), IA-64 (Itanium) SPARC, PPC, ARM64, etc., ya cuentan con soporte para los 64-bit y por tanto deberemos activarla. En caso de estar usando procesadores más clásicos o retro, como los pertenecientes a ISAs IA-32, ARM (arm, armhf), PPC32, etc.
- General setup: aquí se aglutinan algunas de las opciones generales de configuración de nuestro kernel. Por ejemplo, puedes seleccionar la Kernel Compression o compresión que tendrá la imagen del kernel (lz4,...). También puedes usar opciones de compilación cruzada o Cross-compiler, es decir, si por ejemplo queremos construir o compilar un kernel para una arquitectura diferente a la nativa de nuestra máquina, debemos usar estas opciones. Imagina que quieres construir un kernel Linux para funcionar en un ARM desde tu PC que es un x86, entonces la compilación cruzada es lo que lo hace posible, de lo contrario constuirá un kernel compatible con la arquitectura nativa. Si lo deseas también puedes especificar un nombre de máquina o Hostname, si deseas marcar un Initial RAM, si quieres que se construya con características para sistemas embebidos con Embedded system, si queremos características de seguridad como SLAB, etc.
- Enable loadable module: activa o desactiva la carga de módulos dinámica, es decir, si está desactivado funcionará como un kernel monolítico. Es decir, todos los controladores estarán integrados en la imagen del kernel, obteniendo un núcleo bastante grande y pesado, pero consiguiendo que todas sus funcionalidades estén ya cargadas desde el inicio. En cambio, si lo dejamos activo conseguimos algo similar al microkernel, es decir, un núcleo con los controladores imprescindibles y la capacidad de cargar o descargar módulos de forma dinámica durante el uso del sistema según se necesite. Por ejemplo, si tienes un controlador USB cargado como parte del kernel, entonces tendrás funcionalidad USB durante el arranque del sistema, y si lo tienes como módulo, éste debe cargarse para que el dispositivo USB funcione durante la ejecución del sistema operativo.
- Enable block layer: si quieres que tu sistema posea manejo de dispositivos de bloques, entonces habilitalo. Es decir, para dispositivos que trabajan con bloques de datos o en paralelo como las unidades de almacenamiento (discos duros,...), etc. Debes saber que en el mundo Unix se diferencia entre dispositivos de bloques y de caracteres (serie).
- Processor type: otra parte del menú muy importante, ya que permite optimizar el código del kernel que se va a construir para una arquitectura o modelo de CPU específico, lo que hará que se ejecute de una forma más fluida y mejor seleccionando tu microprocesador desde el submenú Processor family. Además, también podrás activar o desactivar otras tecnologías y características como DMA o acceso directo a memoria que debería estar activo para la mayoría de sistemas modernos, evitando así sobrecarga de la CPU en los accesos a memoria que provienen del E/S. SMT se refiere a las tecnologías de procesamiento de hilos o threads en paralelo, como lo es Intel HT (HyperThreading). Otras características que encontrarás aquí son el soporte para EFI, en aquellos sistemas que no usan BIOS. Y también Maxim number CPU, o el número de CPUs que tiene el sistema en caso de tener un sistema multiprocesador.
- Power Manager: es aquí donde podrás configurar algunos parámetros como los que permitirán que el sistema pueda hibernar, ponerse en modo suspensión, etc., es decir, los relativos a la gestión de energía. Aquí tendrás también las opciones de los gobernadores que funcionarán en CPU Frequency para que modifiquen la frecuencia en función de la carga de trabajo y que ahorren energía cuando se pueda. Y en CPU Idle se podrá configurar también otras funciones referentes al volaje el apagado o encendido de núcleos desocupados, etc. Los modelos comerciales de Intel y AMD suelen incluir marcas registradas que hacen referencia a estas funcionalidades como Intel SpeedStep, AMD Power Now!, etc.
- Bus options: encontrarás las opciones de configuración de los buses soportados y sus características.
- Execute file format: puedes seleccionar los ejecutables o binarios que el sistema soportará, por lo general son los ELF y ELF64. A pesar de que GNU GCC sigue generando por defecto binarios con nombre a.out cuando escribimos y compilamos algún programa... pero en realidad ese formato ya está en desuso y a pesar de su nombre son ELF.
- Networking support: protocolos, dispositivos y tecnologías de red que queremos. Por ejemplo, podemos marcar la interfaz de red (tarjeta de red), los protocolos de comunicacion en Networking options, etc.
- Device driver: controladores o drivers de dispositivos que incluirá nuestro kernel. Deberemos marcar los que queramos que se carguen dentro del kernel como los de disco (SATA, IDE, etc.) y que son necesarios para la carga del sistema, o como módulos aquellos que no son imprescindibles para que el sistema inicie (tarjeta de sonido, webcam, HID, Wifi,...).
- Firmware: aquí podemos configurar algunas otras opciones del firmware del sistema, BIOS, etc.
- File system: también bastante interesante, ya que aquí activaremos los FS o sistemas de archivos que estarán soportados. Por ejemplo, ZFS, btrfs, ext3, ext4, ReiserFS, etc.
- Kernel hacking: aquí podemos realizar algunas modificaciones del kernel muy avanzadas, como las famosas combinaciones de teclas Magic SysRq Key que podemos usar para recuperar el sistema de ciertos eventos. También tendremos opciones de desarrollo como la depuración del kernel (debbugging), etc.
- Security options: muy de actualidad ahora que se da tanta importancia a la seguridad. Encontrarás multitud de opciones para mejorar la seguridad del kernel. Por ejemplo, puedes elegir entre SELinux y AppArmor, sería posible activar ambos pero no lo recomiendo porque podría haber conflictos. También existen otras alternativas a estos sistemas de protección como puedes comprobar, e incluso otros sistemas de protección de desbordamingo, protección del kernel, etc.
- Cryptographic: son también otras opciones de seguridad, ya que se refieren a los modelos de cifrado y algoritmos que estarán soportados (AES, DES, ICE, Blowfish, RSA, DSA, etc.).
- Virtualization: encontrarás multitud de opciones para activar o desactivar características y tecnologías para la virtualización completa, la paravirtualización, contenedores, etc.
- Library routines: y bueno, por último, el menú de rutinas de bibliotecas...
Por cierto, si te encuentras con características marcadas como New o Experimental quiere decir que se han agregado a la versión que estás configurando recientemente y no estaban presentes en la versión anterior y que se están desarrollando (pueden no ser demasiado estables o funcionales) respectivamente. En principio, a menos que sepas lo que haces, no te recomiendo que incluyas características experimentales para que el nucleo sea estable.
Introducción a la gestión de procesos y threads en Linux
Me animo con otro tutorial después de haber creado el anterior y espero nuevamente que os guste y os sirva de ayuda. En esta ocasión vamos a explicar un poco qué es eso de los procesos y los hilos de ejecución, o hebras o threads... como los quieras llamar. Ten en cuenta, que todo el software que ejecutas necesita una serie de procesos y/o de hilos que son unidades fundamentales de procesamiento. El scheduler o planificador del kernel Linux las gestionará e irá añadiendo a la cola para que la CPU las vaya ejecutando, accediendo a los datos e instrucciones almacenados en la memoria RAM. Bien, esto es una forma resumida y sencilla de explicar a groso modo el funcionamiento.
Procesos
Pero... ¿qué es un proceso? En los modernos S.O. se trabaja con procesos, que es cómo el sistema trata a programas o tareas específcias en ejecución. Cada uno de ellos posee un espacio de direciones asociado en el que puede leer y escribir en memoria virtual (ya que puede que no se encuentre en la RAM, sino en la memoria de intercambio o Swap y se vaya moviendo de una a otra en función de la prioridad y lo que dicte el planificador). En dicho espacio se almacenarán las instrucciones (código) y datos (constantes, variables,...) que el proceso debe manejar para poderse ejecutar, y por supuesto también su pila o stack. Cuando uno de estos procesos es asignado a una unidad de procesamiento o núcleo de la CPU, ésta comenzará a ejecutarlo y para ello se necesita asignar un conjunto de registros para cada proceso, cargar un registro PC (Program Control) que irá apuntando a la siguiente instrucción del código del programa que se debe ejecutar tras la que está ejecutándose actualmente, un registro SP (Stack Pointer) y otros registros para los operandos que necesita la instrucción. Básicamente, una vez está todo, la unidad de control de la CPU decodificará la instrucción y comenzará a enviar señales al resto de unidades funcionales para que sepan qué deben hacer, como cargar datos desde registros y llevarlos a la ALU o FPU para hacer una operación como una suma, multiplicación, resta, etc. Una vez se consigue el resultado, se pasa a la siguiente instrucción y así hasta completar todo el código de ese proceso. Una vez se tiene, el proceso ha finalizado... Insisto, es una forma simplista de explicarlo, pero no quiero perder a los menos expertos y entrar en temas de superescalaridad, pipeline, OoOE, especulación, etc.
En Linux, podemos conseguir informacion de los procesos en marcha de muchas formas, pero dos de las mas conocidas son con los comandos:
ps aux
top
El primero muestra los procesos en marcha y el segundo es interactivo, es decir, lo muestra en tiempo real y puedes ver la evolución. Por cierto, para salir de top simplemente pulsa Ctrl+C. Si quieres verlos en forma de árbol, y ver la geneaología y de dónde cuelga cada proceso (como sabes, todos vienen del proceso PID=1 o Init, aunque si no usas SysV, este proceso podría denominarse de otra manera, como systemd), puedes usar:
pstree
Una serie de sistems del kernel, como el planificador citado anteriormente y el IPC (Inter-Process Communication) se encargarán de gestionarlos y comunicarlos entre sí entre señales. Unas señales que seguramente te suenen del uso del comando kill para matar procesos ¿no? Bueno, si no es así puedes listarlas con:
kill -l
Estas señales son las que usará el kernel para modificar los estados de los procesos. En sistemas tipo Unix, los estados posibles son 7 (los puedes ver en la columna STAT de la salida de ps):
- Ejecutándose: el proceso está en la cola de ejecución para ser procesado por la CPU.
- Interrumpido: se ha interrumpido por el planificador o está durmiendo a la espera de ser despertado por una señal o temporizador y pasar a ejecutarse.
- Sin interrupciones: dormido como en el caso anterior, pero puede ser despertado por eventos externos.
- Zombie: el proceso ha terminado, pero falta liberar recursos de hardware que tiene ocupados. Es decir, está muerto pero el sistema lo considera vivo... y esos recursos de hardware no pueden ser asigandos a otro proceso.
- Parado: ha sido detenido por una señal de control o por ptrace.
- Exclusivo: cuando se encuentra dormido o en la cola de ejecución esperando a ser despertado sin necesidad de desperar a los otros procesos. Es decir, no es dependiente de otros y puede ser ejecutado sin necesidad de ejecutar otros previamente.
- Terminado: en realidad no se hace referencia a este estado en el sistema, ya que no es un estado en sí, solo es teórico. Es lógico, ya que cuando un proceso ha terminado ya no está en ningún estado, simplemente ha sido ejecutado y ya no existe.
Threads
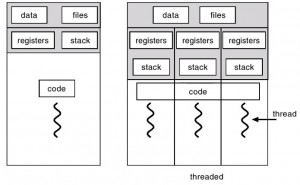
Eso en cuanto a procesos. ¿Qué sucede con los hilos o threads? No quiero que los confundas con subprocesos, si te fijas en la salida del comando pstree, hay procesos padre e hijos que cuelgan de estos, es decir, que han sido iniciados por el padre. Pero tanto los padres como los hijos no dejan de ser procesos. Los hilos son procesos ligeros en los que se puede dividir cualquier proceso, y por definición sería la unidad de procesamiento más pequeña que puede planificar un sistema operativo. Cada proceso, si se usa programación multithread, está dividido en varios hilos y para que dicho proceso finalice y pase a ese no-estado "terminado" todos y cada uno de sus hilos deben haber finalizado su ejecución.
A diferencia de los procesos, que tenían sus propios recursos asignados, los hilos que pertenecen a un mismo proceso compartirán los recursos asignados a dicho proceso. Aunque, evidentemente de algún modo se deben diferenciar entre sí y eso se consigue asignando a cada thread unos recursos específicos como la pila y el registro de estado de la CPU, etc. Como curiosidad, para generar los procesos, el kernel Linux usa la syscall o llamada al sistema denominada fork(), mientras que para los hilos se usa clone().
Gestión de procesos
Bien, ahora que ya sabemos qué son los procesos e hilos, vamos a ver cómo Linux los gestiona. Y antes de eso, debemos conocer qué es el contexto. Resulta que el planificador irá moviendo los procesos o hebras de la cola de ejecución según la prioridad necesaria. Por eso, si un proceso poco prioritario está en la cola y aparece otro con mayor prioridad, puede sacar al primero de la cola e introducir al segundo. En caso de interrumpir el proceso/hebra, se necesita guardar su información en algún lugar para luego poderlo recuperar. Eso se hace en una parte de la memoria que guardará su estado y que junto con el programa, se conoce como PCB. Todo esto, unido a una serie de algoritmos implementados por software que compondrán el planificador, hará que la gestión de los procesos sea transparente para el usuario y que nosotros solo nos dediquemos a abrir y cerrar apps o realizar tareas dejándole toda la tarea al kernel.
Sin entrar en demasiados detalles de qué es /proc, simplemente que sepas por el momento que es un espacio o interfaz para el usuario en la que el kernel nos muestra la información de procesos. Si te diriges a ese directorio verás un montón de ficheros y directorios numerados. Cada directorio pertenece a un proceso. Por ejemplo, el directorio 575 corresponde con el proceso PID=575. Dentro de dicho directorio, o cualquier otro (solo es un ejemplo), encontrarás unos ficheros como:
- cmdline: nombre del programa o comando que inició el proceso
- cwd: enlace simbólico al directorio de trabajo del proceso
- environ: nombres y valores de variables que maneja el proceso
- exe: enlace simbólico al ejecutable original
- fd: directorio con el enlace hacia el descriptor de fichero
- fdinfo: directorio con entradas que describen la posición y banderas del descriptor
- maps: información sobre el mapeado de ficheros y bloques
- mem: binario que representa la memoria virtual usada por el proceso
- root: enlace hacia el directorio raíz del proceso
- status: información del estaod del proceso y uso de memoria
- task: enlaces duros para cualquier tarea...
Bien, si volvemos al tema de los procesos y demás, ya sabes que puedes conseguir también información de ellos con:
ps aux
O la sintaxis equivalente:
ps -ef
Veremos los procesos en marcha listados con una serie de columnas con información. Si usas la opción -u de ps seguida del nombre de usuario solo se listan los procesos de dicho usuario. Por ejemplo:
ps -u root
En cualquier caso, las columnas que nos muestra son:
- USER: el usuario al que pertenece el proceso.
- PID: el ID o identificador del proceso.
- %CPU: porcentaje de CPU usado.
- %MEM: porcentaje de memoria usada.
- VSZ: tamaño de la memoria virtual total usada por el proceso.
- RSS: conjunto de residentes o memoria del proceso que está en la RAM. La otra parte estará en la SWAP.
- TTY: la tty en la que se ejecuta
- STAT: el estado del proceso, si recuerdas había 7, mediante letras se mostrará el estado.
- START: cuándo se inició
- TIME: tiempo que dura
- COMMAND: es el programa o binario al que pertenece el proceso.
Y fijate qué curioso, si añadimos una L a nuestras opciones de ps conseguimos un misterioso cambio en las columnas:
ps -efL
Ahora aparecen dos columnas especialmente interesantes para el tema que tratamos. Una es PPID, es decir, el Parent Process ID. Como su nombre indica es el ID del proceso padre del que cuelga este proceso. Pero hay una columna que me interesa aún más, y es LWP (Lightweigh Process). ¿Te suena? Pues sí, es un proceso ligero o thread. En esta columna por tanto aparece el ID del thread. Verás que hay PIDs con un solo LWP, porque no son programas que soporten multithread, pero en otros PID habrá varios LWP para un mismo PID, en ese caso, dicho proceso sí que está fraccionado en hilos.
Y ahora viene la pregunta del millón. ¿Un proceso se puede matar como se matan procesos con kill? La respuesta es NO. Se puede matar a procesos padre o a procesos hijo, lo digo porque incluso en muchos blogs especializados hay verdaderos follones en la terminología y dan a entender que un thread se puede matar con kill de forma independiente y no es cierto. La creación o muerte de los threads solo se puede hacer desde el código fuente, mediante la programación de funciones que los generan o eliminan, pero una vez el programa se está ejecutando no podemos usar kill o ninguna otra herramienta para liquidarlos a nuestro antojo...
Si lo piensas es lógico. Imagina que un proceso que estás ejecutando es la preparación de una tarta. Dicho proceso se divide en 3 threads: la mezcla de los ingredientes para hacer la masa, vertir la masa en el molde y hornear la masa. ¿Podría saltar o eliminar el primer paso de mezclar los ingredientes? Es absurdo, el resultado sería algo erróneo, un molde sin contenido horneado...
Vea nuestra política de cookies y enlaces de interés aquí

© 2018 Creative Commons By-NC : SLIMBOOK™
«Linux Center» is an authorized independent project with sublicense number 20171225-0743 of Linux® registered trademark of Linus Torvalds.
